Mastering Kubernetes – How Monitoring Fuels Performance,Scalability And Operational Efficiency
Kubernetes cluster monitoring provides essential advantages for organizations, starting with proactive issue detection. By continuously tracking system metrics, teams can identify potential problems early, reducing downtime and boosting reliability.
Improved performance is another key benefit, as monitoring helps pinpoint bottlenecks and optimize resource allocation, ensuring smooth application operation.
Scalability management is seamless with real-time insights into resource usage and traffic patterns, allowing organizations to dynamically adjust applications to meet fluctuating demands.
Additionally, automated monitoring enhances operational efficiency by minimizing manual intervention, enabling teams to focus on innovation instead of troubleshooting.
Together, these benefits establish a robust monitoring strategy that helps organizations maintain high performance, optimize resources, and achieve operational excellence in their Kubernetes environments.
Proactive Issue Detection
Proactive issue detection in Kubernetes helps identify potential failures before they impact performance, such as resource exhaustion or application errors.
Key benefits include reduced downtime, improved user experience, quicker resolution of issues, and enhanced reliability. This foresight enables teams to maintain operational efficiency and optimize resource allocation effectively.
Improved Performance
Improved performance in Kubernetes enhances application responsiveness and stability, particularly during peak traffic or resource-intensive operations. Key benefits include faster load times, increased user satisfaction, optimized resource utilization, and reduced latency.
By continuously monitoring and fine-tuning performance, organizations can deliver seamless experiences and maintain competitive advantages in the market.
Scalability
Scalability in Kubernetes is essential for handling fluctuating workloads, such as sudden traffic spikes during promotions or seasonal events.
Key benefits include seamless resource allocation, cost efficiency, and improved application availability.
By automatically adjusting resources, organizations can ensure optimal performance and user satisfaction, while minimizing downtime and operational costs.
Operational Efficiency
Operational efficiency in Kubernetes streamlines resource management and reduces manual intervention, particularly in automated deployments and monitoring.
Key benefits include faster incident response times, enhanced team productivity, and cost savings.
By optimizing workflows, organizations can focus on innovation and development, ultimately driving growth and improving service delivery.
Choosing the Right Tools for Kubernetes – A Guide to Effective Monitoring
In the Kubernetes ecosystem, companies prefer these tools for their open-source nature, scalability, and robust community support, allowing for flexible integration into existing workflows. By leveraging these tools, organizations can achieve comprehensive monitoring and observability, leading to improved performance, proactive issue resolution, and enhanced operational efficiency.
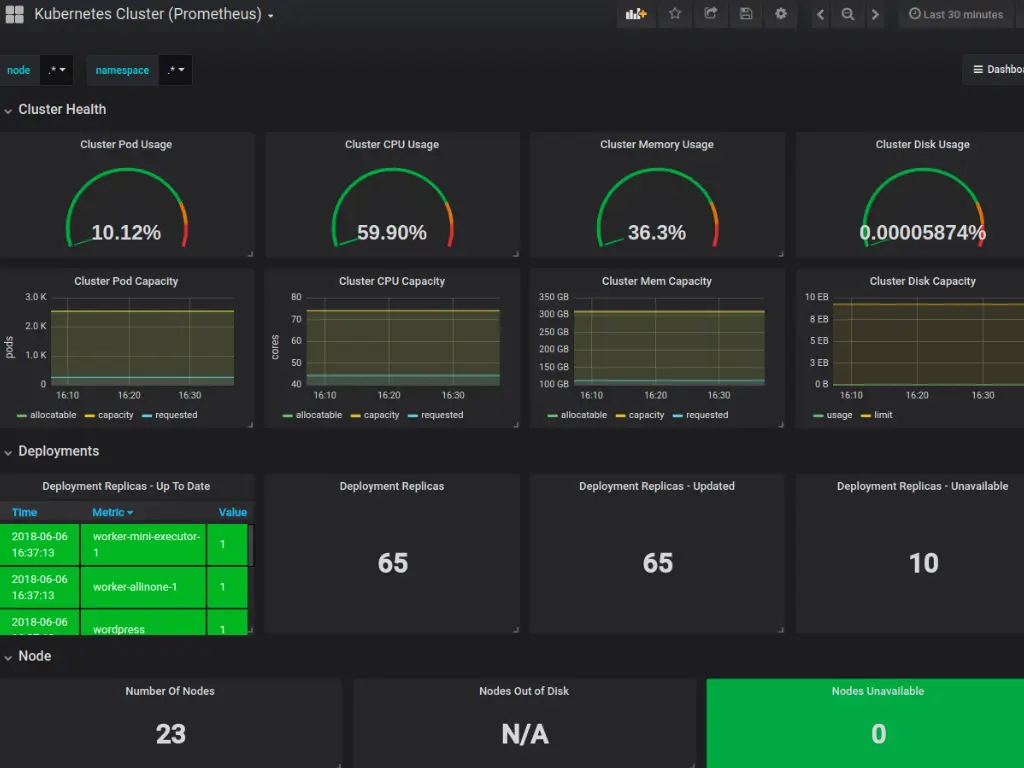
Prometheus
Prometheus excels in monitoring dynamic environments, particularly for applications with microservices architectures. It helps organizations track performance metrics, resource utilization, and system health in real time.
Key strengths include powerful querying capabilities, built-in alerting, and seamless integration with Kubernetes. By providing actionable insights, Prometheus enables proactive issue detection and resolution, ensuring optimal application performance and reliability.
Grafana
Grafana is invaluable for visualizing metrics and logs from various data sources, making it ideal for monitoring Kubernetes clusters.
Organizations prefer Grafana for its customizable dashboards, support for multiple data sources, and intuitive user interface. By transforming complex data into clear visualizations, Grafana helps teams quickly identify issues, track performance trends, and enhance operational efficiency.
ELK Stack
The ELK Stack (Elasticsearch, Logstash, and Kibana) is essential for centralized log management and analysis in Kubernetes environments. It helps organizations aggregate logs from various sources, making it easier to troubleshoot issues and monitor application behavior.
Companies prefer ELK for its powerful search capabilities, real-time data analysis, and interactive visualizations. By providing comprehensive insights into system performance and security, the ELK Stack enables proactive incident response and enhances overall observability.
Apache Superset
Apache Superset is essential for organizations seeking to visualize and analyze cloud infrastructure monitoring data, including Kubernetes clusters.
It enables teams to create interactive dashboards that track metrics from various monitoring tools and Kubernetes resources.
Organizations prefer Superset for its intuitive interface, robust SQL support, and seamless integration with diverse data sources. By facilitating effective data analysis, Superset empowers teams to monitor Kubernetes performance, optimize resource usage, and make informed decisions that enhance overall cloud infrastructure management.
Jaeger
Jaeger is crucial for tracing requests in microservices architectures, helping organizations analyze performance bottlenecks and latency issues. It excels in providing end-to-end visibility of transactions across distributed systems.
Companies prefer Jaeger for its ability to visualize complex service interactions, identify problematic services, and optimize performance. By facilitating deep insights into request flows, Jaeger enhances troubleshooting and improves overall application efficiency.
OpenTracing
OpenTracing is beneficial for organizations adopting microservices, as it provides a vendor-neutral API for distributed tracing. It helps teams standardize tracing across various instrumentation libraries, ensuring compatibility and flexibility.
Companies prefer OpenTracing for its ability to provide context for request flows, identify latency issues, and enhance observability. By simplifying the implementation of tracing, OpenTracing facilitates better performance monitoring and troubleshooting.
Securing Your Kubernetes Environment – Best Practices for Effective Monitoring
Implementing best practices for Kubernetes monitoring is essential to ensure the reliability, performance, and security of your applications. Proper monitoring not only helps identify issues proactively but also enhances operational efficiency and resource optimization. Adhering to these best practices allows organizations to maintain robust observability while minimizing potential risks associated with complex environments.
Centralize Logging and Metrics
Centralizing logs and metrics from all components of your Kubernetes cluster is crucial for effective monitoring.
Use tools like the ELK Stack or Prometheus to aggregate data in one location, enabling easier access and analysis. This approach allows teams to gain a holistic view of system performance and quickly identify anomalies, leading to faster incident resolution.
Implement Role-Based Access Control (RBAC)
To enhance security, implement Role-Based Access Control (RBAC) for your monitoring tools and Kubernetes resources.
RBAC ensures that only authorized users can access sensitive metrics and logs, reducing the risk of data breaches or unauthorized modifications.
By defining precise roles and permissions, you can maintain a secure environment while enabling your team to monitor effectively.
Set Up Alerts with Context
Configuring alerts based on critical metrics is vital for proactive issue detection.
Ensure that alerts are not only set for thresholds but also include contextual information to aid in troubleshooting. For example, alerts should specify which component is affected and provide relevant metrics.
This context empowers teams to respond more effectively, minimizing downtime and improving overall system reliability.
Conclusion
In today’s digital landscape, choosing Kubernetes monitoring is vital for the success and security of your business.
By implementing effective monitoring practices, you gain unparalleled visibility into your applications, enabling proactive issue detection and optimal resource management.
This not only enhances performance but also proves to be cost-effective, as it minimizes downtime and reduces operational risks.
Kubernetes represents the modern approach to managing complex applications, and robust monitoring is an integral component of this strategy. By prioritizing Kubernetes monitoring, you empower your organization to achieve operational excellence, safeguard your infrastructure, and drive innovation, ensuring that you stay ahead in a competitive market.
Invest in Kubernetes monitoring today to unlock the full potential of your applications and support your business’s long-term success.